Future-Proofing Your Database: Escaping MongoDB Schema Anti-Patterns

Overview
MongoDB’s flexible document model is a powerful asset, but with great flexibility comes the great responsibility of proper design. Unlike relational databases that enforce strict structure, MongoDB allows you to create your own structure, and it’s easy to fall into schema design anti-patterns that severely cripple performance, scalability, and maintainability.
This article outlines the most critical MongoDB schema anti-patterns and provides some guidance on how to avoid them.
MongoDB Schema Anti-Patterns
Let’s list the most common schema anti-patterns for MongoDB. The following sections will elaborate on each of these Anti-Patterns with examples.
Massive Arrays or Expanding Arrays in the Document
Large no of Collections
Missing or Inappropriate Indexes
Massive Arrays Or Expanding Arrays in the Document
MongoDB offers flexibility in using different data types within documents. This anti-pattern occurs when there is an array of embedded documents part of a single parent document.
This anti-pattern can exceed the 16 MB document limit set for MongoDB documents, as the embedded array size may grow. Additionally, this anti-pattern can degrade write performance when updating documents, as each new array element will necessitate a document update.
To elaborate further, let’s consider an example of a retail Franchise/Brand as a MongoDB Document and Stores of a Franchise as an array of embedded documents. Below is the representation of the Franchise document with an embedded array of Franchise Store documents.
{
“_id”: {
“$oid”: “6886f4a4c4000515fa32c494”
},
“name”: “testFranchise”,
“description”: “test franchise for beverage”,
“isActive”: false,
“isDeleted”: false,
“owner”: “testOwner”,
“attributes”: {
“beverage”: “tea”
},
“address”: {
“_id”: “test-addr”,
“address”: “ABC”,
“pincode”: “411021”,
“country”: “INDIA”,
“state”: “MH”,
“city”: “nagar”
},
“stores”: [
{
“_id”: {
“$oid”: “6886f5470b5546496e68f80a”
},
“name”: “testStore”,
“description”: “test store for beverage”,
“franchiseId”: “6886f4a4c4000515fa32c494”,
“address”: {
“_id”: “test-addr”,
“address”: “ABC”,
“pincode”: “411022”,
“country”: “INDIA”,
“state”: “MH”,
“city”: “nagar”
},
“attributes”: {
“beverage”: “tea”
}
},
{
“_id”: {
“$oid”: “6886f5470b5546496e68f8bb”
},
“name”: “test-Store-2”,
“description”: “test store for beverage”,
“franchiseId”: “6886f4a4c4000515fa32c494”,
“address”: {
“_id”: “test-addr-pune”,
“address”: “ABC”,
“pincode”: “411028”,
“country”: “INDIA”,
“state”: “MH”,
“city”: “pune”
},
“attributes”: {
“beverage”: “tea”
}
}
]
}The store array could keep growing as the franchise adds/opens more stores in the future.
This anti-pattern could be avoided by adopting/implementing the schema design as below
{
“_id”: {
“$oid”: “6886f5470b5546496e68f8bb”
},
“name”: “test-Store-2”,
“description”: “test store for beverage”,
“address”: {
“_id”: “test-addr-pune”,
“address”: “ABC”,
“pincode”: “411028”,
“country”: “INDIA”,
“state”: “MH”,
“city”: “pune”
},
“attributes”: {
“beverage”: “tea”
},
“franchise”: {
“id”: “6886f4a4c4000515fa32c494”,
“name”: “testFranchise”,
“description”: “test franchise for beverage”,
“isActive”: false,
“isDeleted”: false,
“owner”: “testOwner”,
“attributes”: {
“beverage”: “tea”
}
}
}In the above example, the Store document contains Franchise information. This removes the risk of an ever-growing array of Store documents that were embedded as part of the Franchise Document.
Large no of Collections
With MongoDB, today, one can create a document collection per document type. So if a product or an application is using MongoDB to store data for its domain objects, etc., and if the product overall deals with more than 5000 domain objects, it would eventually create 5000 collections, each collection having documents related to a domain object. Storing more collections in MongoDB is an anti-pattern, as it may degrade the performance of the database overall. As of today, MongoDB recommends having 10000 collections.
To avoid this anti-pattern, one could adopt the Single Collection Schema Design pattern, following the Domain Driven design, putting the domain objects applicable to the bounded context in a single collection, and differentiating documents for each domain object by the DOC_TYPE field.
To elaborate further, let’s consider an example of a Product Support Case. The support case could have conversations with the customer related to the case. It could also have different documents related to the customer, like KYC or other supporting documents related to the case, and other domain objects, a product support case could have. As mentioned, MongoDB is the data store for the product to store data for its domain objects.
Consider initially that each domain object would have a separate collection for the documents. See below the representation of documents for domain objects(Specifically conversations) in the different collections.

Avoid the Anti-Pattern - Adopt the Single Collection Schema Design Pattern

In the above example, each document is a conversation and has a DOC_TYPE field to differentiate the type of conversation document it is. This allows applications to create a single collection by storing the different document types of a similar domain/context together.
Missing or Inappropriate Indexes
Assuming MongoDB will just handle performance, or creating indexes on fields that are never queried, or creating massive indexes on low-cardinality fields. This is an anti-pattern, as the application could run filtered queries on a large collection without creating an index on the filter field. This could result in a collection scan, which would degrade query performance.
Another example of an anti-pattern is creating an index on a Boolean field, which can only have two values: true or false. An index here would not be of much help. Creating such indexes can waste resources like disk and memory, leading to performance issues while writing data, where these indexes would also be updated.
To avoid this anti-pattern, use explain() to understand what indexes the query is using when it executes. MongoDB also provides index stats on the Atlas UI(if you are using Atlas ), indicating what indexes are most used and which are not heavily used. This way, users could delete the unwanted indexes to save resources, which gradually improves database performance. The analysis also helps users understand the query pattern and what indexes could be required to be added or dropped in the future.
Screenshot of Atlas UI Showing Index usage.
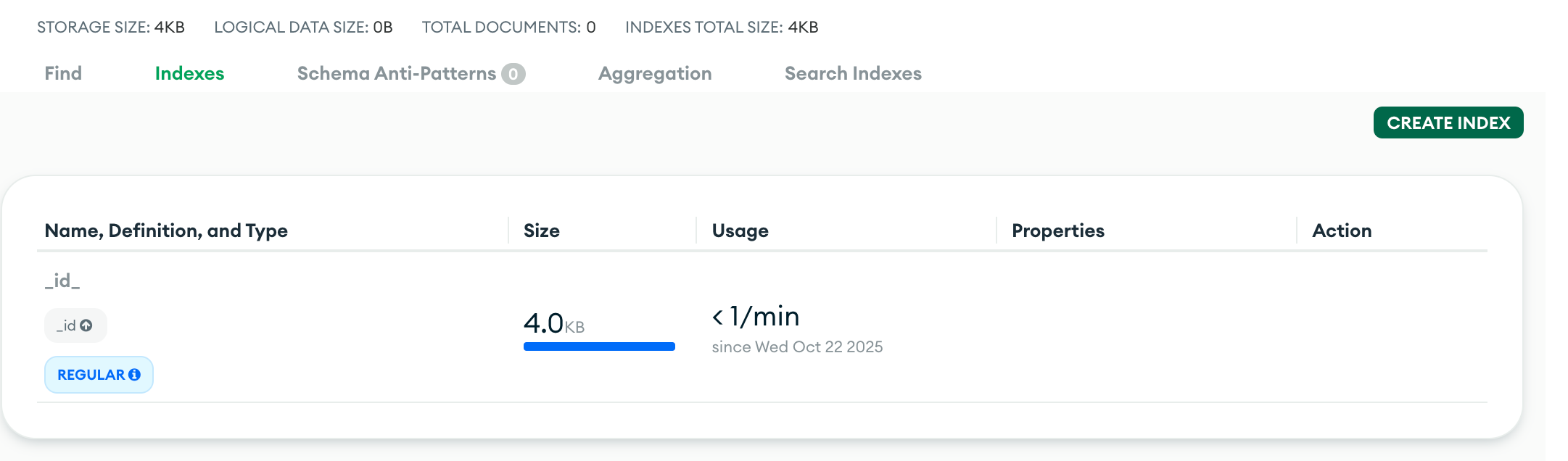
Atlas also provides suggestions on which indexes to drop and create to improve performance through Performance Advisor(available only for paid users).
Conclusion
By adopting an approach that prioritizes embedding for cohesion, referencing for scale, and targeted indexing for speed, developers can harness the true power of MongoDB’s document model and avoid common performance pitfalls.